Integrations
Contents
Integrations#
JupyterLab#
The overall roadmap for RTC in JupyterLab is defined in the Real Time Collaboration Plan. The discussions to integrate the RTC components into JupyterLab are tracked in jupyterlab/rtc#27.
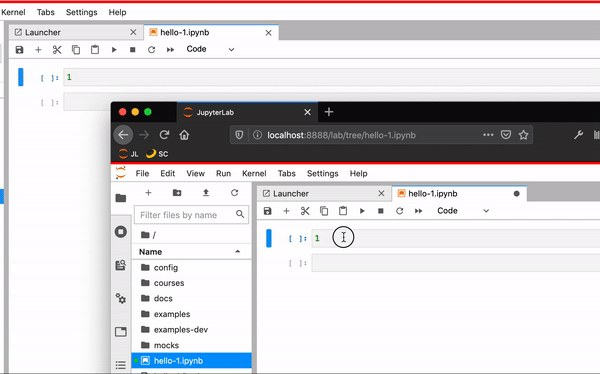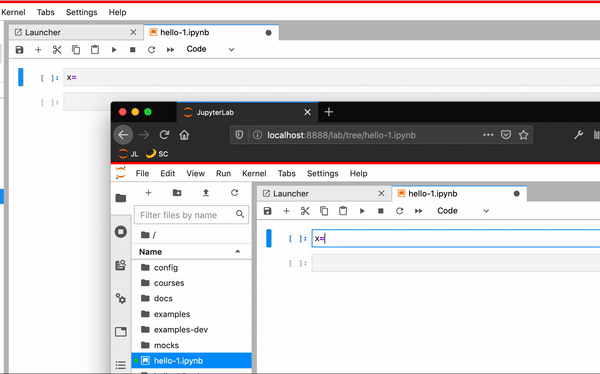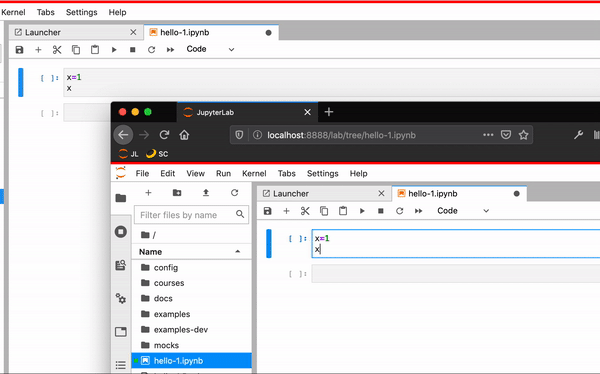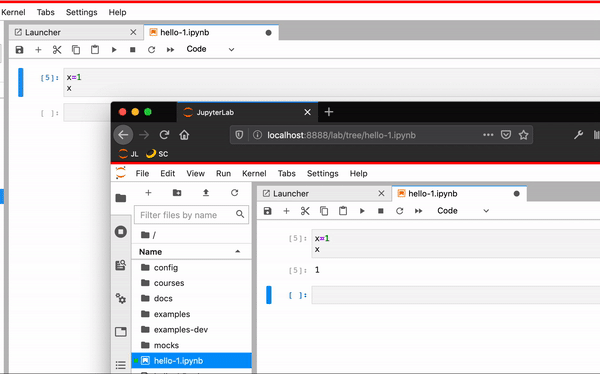
Iteration 1#
At the beginning of 2019, we had two branches for JupyterLab 1.0.3 and Phosphor.js.
https://github.com/vidartf/jupyterlab/tree/rtc, pushed also to https://github.com/datalayer-contrib/jupyterlab/tree/rtc-2019.
https://github.com/vidartf/phosphor/commits/feature-tables3-extras, pushed also to https://github.com/datalayer-contrib/jupyterlab-lumino/tree/rtc-2019.
You can try this first iteration with a Dockerfile that lives in https://github.com/ellisonbg/jupyterlab-rtc, repository also forked to https://github.com/datalayer-contrib/jupyterlab-rtc-docker-2019-1.
docker run -p 8888:8888 ellisonbg/jupyterlab-rtc start.sh jupyter lab --dev-mode --no-browser
Iteration 2#
A continuation of this work had been done in the second half of 2019. Most of the work for that second attempt is living in:
Iteration 3#
We have ported Iteration 1 to begin-August 2020 JupyterLab and Lumino master in the following 2 branches.
https://github.com/datalayer-contrib/jupyterlab/tree/rtc-2019-master
https://github.com/datalayer-contrib/jupyterlab-lumino/tree/rtc-2019-master
We have also ported Iteration 2 to end-August 2020 JupyterLab and Lumino master branches. The toc, logconsole, celltags and debugger extensions have been disabled as they have been recently added to JupyterLab code base. If it makes sense, we could update them also.
https://github.com/datalayer-contrib/jupyterlab/tree/rtc-2019-2-master
https://github.com/datalayer-contrib/jupyterlab-lumino/tree/rtc-2019-2-master
You can compare with the changes:
https://github.com/jupyterlab/jupyterlab/compare/f2ce97034efc69f9ad565d92ec8370ccca6eb160…datalayer-contrib:rtc-2019-2-master
https://github.com/jupyterlab/lumino/compare/1116776621689093766a6e992de5abd05cedaf8c…datalayer-contrib:rtc-2019-2-master
WIP Iteration 4#
The next step is to define how to integrate the components developed in this repository at the light of these learnings. The behavior (features and limits) of Iteration 3 are the same as Iteration 2. For example saving notebook does not persist the ipynb file. We have copied here the latest public status meeting on the JupyterLab PR.
2019.11.13 meeting
Ian: Lifecycle is fragile for notebooks.
- Deciding whether to initialize a new document, whether to insert text from disk. It's working now but a little hacky.
- Ian's idea: The server should be in charge of saying whether a document is initialized. For example, if two people connect at the same time it should only be initialized once.
Why are there two paths?
- to support fully client side Lab.
- a text editor expects text editor schema, which has cursor position, etc. A cell supports text editor schema + other things like outputs, execution count. So the cell creates it's own datastore and passes in the model.
What about an ORM like redux-orm? Worth exploring having helpers to explore ORM references.
- this does it currently https://github.com/jupyterlab/jupyterlab/blob/55fbac91507ea5119665244ce3b136b71d4e7c62/packages/cells/src/data.ts#L238-L250
- We are doing this currently with record locaters: https://github.com/jupyterlab/jupyterlab/blob/55fbac91507ea5119665244ce3b136b71d4e7c62/packages/notebook/src/data.ts#L36
It works currently for text documents and notebooks.
We should have per document datastore, because that's where undo/redo makes sense.
Blockers on phosphor side?
- unpaired surrogate issue. Library generates a byte string. Each patch gets an ID. IDs can be absolutely ordered, so this is how we resolve conflicts. Generate these IDs involves a lot of bitwise logic. And there is a problem with the scheme, because it can generate invalid UTF strings, because it can generate unpaired surrogates. Then it doesn't serialize properly.
How do we support this package?
Two points:
1. Can we make this is a separate package and market it to general JS?
- Create a community around this before.
- Almost a useful package
- UTF 8 issue
- some patches are large
- automerge
- Not huge community
- not type safe table
- Ian: Nervous about adopting this. Main cost is a lot of churn without a huge benefit. What if we adopted this just for client side, without server side? We would a lot of changes with undo/redo.
Phosphor
- UTF8 bytestring issue "unpaired surrogate"
- Patches are too large
- It might be possible to allocate ID range space more efficiently when pasting
JupyterLab
- "Lifecycle events" if two open a notebook a notebook at once
- What to handle server side
Options
- Pass on RTC for now
- Merge in existing work, after fixing a few things
- Create separate repo to further explore this and create a reusable frontend JS library around this with backend support
Brian: We need real time collaboration for, undo redo, server side models, multiple tabs, so giving up isn't a viable option
Vidar: The remaining things to do require collaboration JupyterLab project wide to figure out scope.
We could move the datastore code to a new repo, to encourage collaboration potentially and give us some distance from the API as we develop it.